Hello World!
Hace 3 años inició un proceso de transición tecnológica que se materializó con los agentes inteligentes en 2025. En los últimos años me he especializado como desarrollador de Blockchain y contratos inteligentes. Esto aunado al “Bear Market” hizo que la demanda de mis productos y servicios, decayera de manera significativa el último año.
Evidentemente la tecnología de Blockchain no va a desaparecer, pero al igual que los grandes de Silicon Valley están, todos, hoy en día abocados a la Inteligencia Artificial, me parece que la mayoría de las empresas de tecnología y emprendedores, de todo tipo, están orientando sus esfuerzos a ver qué hacen con la IA.
Gartner calificó el 2025 como “El año de los agentes de IA”, y algunos reportes indican que más de la mitad de las empresas están usando “algún tipo de IA”... yo no sé. Quizás sea porque mi entorno es diferente, o esta tecnología no ha llegado con tanta fuerza a Centroamérica, pero creo que todavía hay mucha bulla y poca cabuya, todo el mundo quiere hacer algo, pero hay pocas implementaciones reales.
Es por esto que he decidido arremangarme la camisa y meter mis manos en el asunto. Empezaré a escribir mis modestos descubrimientos y avances para tratar de ver hasta dónde llega esta tecnología, y si realmente se puede poner en práctica en las empresas y clientes de mi entorno.
Agente de Análisis Vocacional
Comencé por lo que tengo mas a mano: PsicoEnLine@, un software de evaluación de pruebas psicométricas, que desarrollé en conjunto con Psico Consult, empresa venezolana de evaluación y selección de personal especializada en pruebas psicométricas y otros instrumentos. Este sistema elabora informes en lenguaje natural (con tecnología prehistórica a punta de if-else y una tabla de comentarios posibles), estos informes son de utilidad para los analistas de recursos humanos en sus procesos de evaluación y selección de candidatos.
Luego de algunas pruebas iniciales con Bedrock (carísimo), con Claude Code (poco amigable), aterricé en n8n (facilísimo y por ahora, baratísimo, es gratis, open source). n8n (en-ei-en) es una herramienta de automatización que se integra muy fácilmente con modelos de lenguaje (LLM). Se vende como una herramienta de low-code, y si, es cierto, hasta ahora no he tenido que “echar mucho código”, pero loro viejo no aprende a hablar (o en mi caso loro viejo no deja de programar), así que siempre termino agregando uno que otro nodito de código para hacer una que otra cosa.
n8n se puede instalar localmente de manera sencilla:
sudo apt install npm
sudo apt install nodejs
sudo npm install -g n8n
sudo n8n start
Inicié mi primer “Hello World!”, un agente simple de análisis vocacional. La idea es simple:
- Usar de entrada un Curriculum, un resultado de pruebas psicométricas, perfil de Linked-in, o cualquier información del candidato a evaluar (notas, breve descripción personal, etc)
- Solicitar los datos básicos del usuario en un formulario sencillo
- Enviar la data relevante a un LLM para que se comporte como un analista de recursos humanos y evalúe el potencial profesional de la persona
- Probar diferentes LLMs para evaluar costos, número de tokens gastados, tipos de respuesta.
- Formatear la respuesta en HTML y enviarla por correo al candidato
El flujo resultante fue:
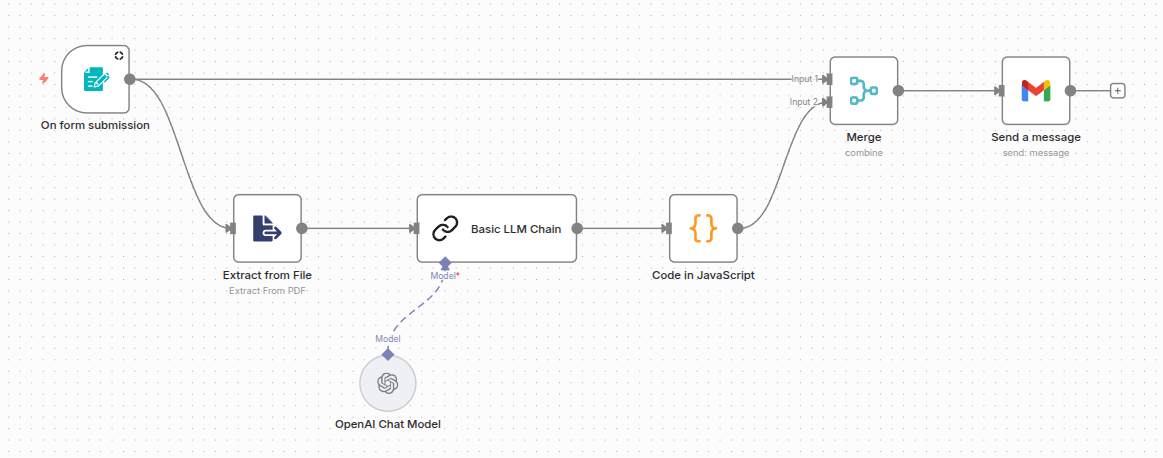
Flujo de trabajo de n8n
Resultados Preliminares
Hice algunas pruebas con varios perfiles, dejo acá un ejemplo del análisis de mi curriculum, y que el agente me envió a mi correo electrónico automáticamente:
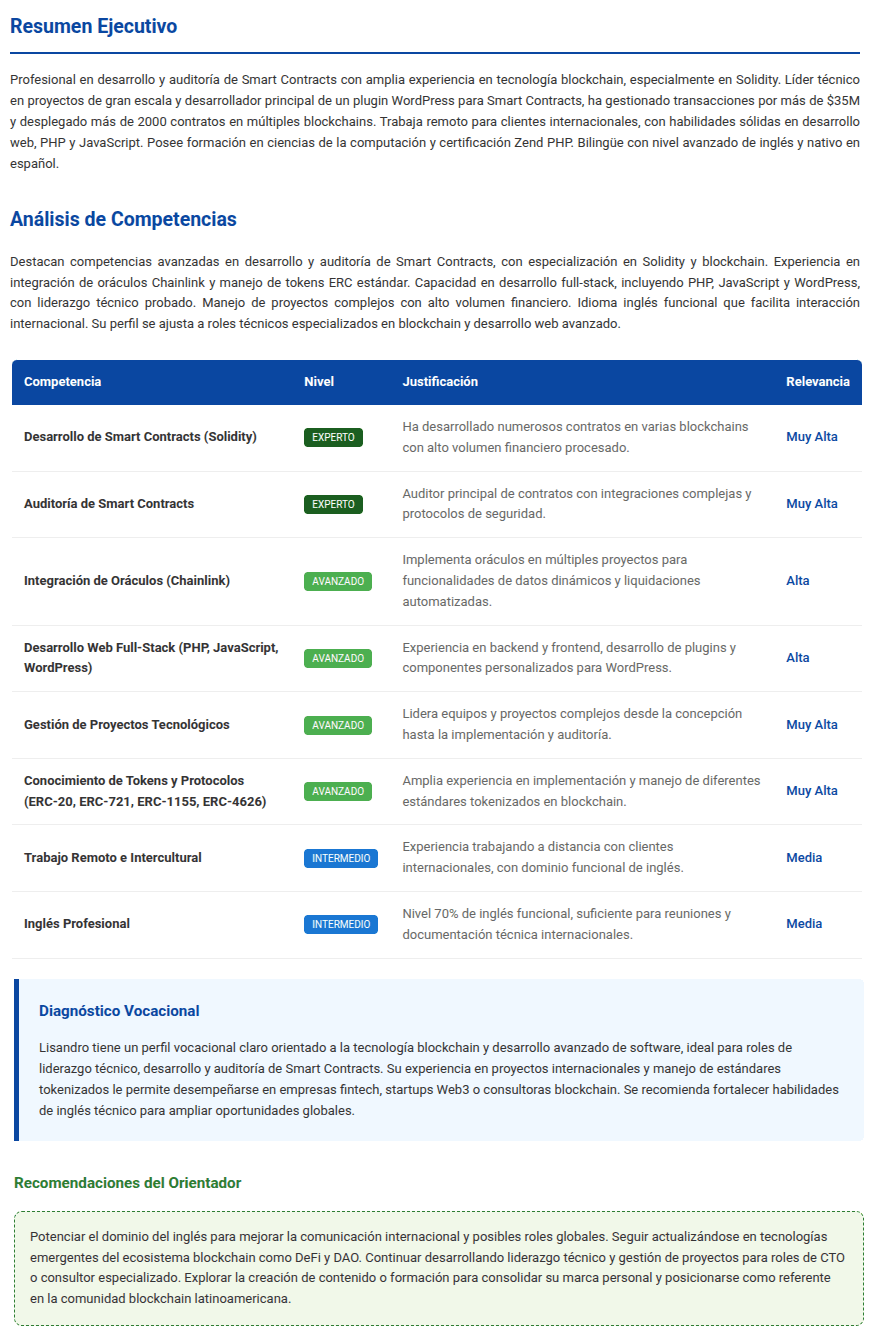
Resultado de Análisis Vocacional
Luego de esto evalué diferentes opciones de LLM diferentes:
- ChatGPT gpt-4.1-mini: Es el modelo pequeño de OpenAI. Es el modelo que está disponible en el chat de manera gratuita, diseñado para un equilibrio entre velocidad y razonamiento.
- openai/gpt-oss-120b: Lanzado en 2025, es el primer modelo open source (open-weights) de OpenAI. Utiliza una arquitectura de expertos (MoE) que lo hace muy eficiente.
- Gemini 2.5 flash lite: Es una versión rápida y económica de la familia Gemini 2.5.
- DeepSeek-chat (V3): Es el modelo insignia de DeepSeek. Utiliza una arquitectura muy avanzada que rivaliza con GPT-4o en capacidad general, pero con un costo operativo mucho menor.
- deepseek-r1:7b: Es un modelo especializado en razonamiento puro. De tamaño pequeño. personales.
Lo primero fue clasificar los modelos por tipos:
- API: son API ofrecidas por empresas, disponibles a un costo por millón de tokens de entrada o salida
- Open Source: son versiones de LLMs también creado por las empresas anteriores, pero que están disponibles públicamente para ser instaladas y usadas de manera independiente.
Los modelos invocados mediante API solo requiren el registro de una cuenta, abonar una cantidad de dinero, en mi caso para pruebas sólo aboné entre 2$ y 10$ a cada uno para hacer pruebas, y sólo gasté algunos centavos.
En cuanto a los de Open Source, solo necesite instalar en mi máquina el de Deepseek-r1 de 7 billones de tokens, porque el Open Source de Open AI lo pude usar usando la API de Groq (si, con “Q” no Grok con “K” de Elon Musk).
La instalación de ollama + deepseek fué muy sencilla y solo tomó algunos minutos:
curl -fsSL https://ollama.com/install.sh | shY para correrlo:
ollama serveLuego de hacer una docena de pruebas localmente en mi Laptop sencilla (AMD Ryzen™ 7 + 16Gb RAM) utilizando n8n de manera local, y el rendimiento fué el siguiente:
Resultados Preliminares
| Modelo | Resultado | Tiempo de Respuesta | Cantidad de Tokens usados |
|---|---|---|---|
| ChatGPT gpt-4.1-mini | Exitoso | 15 segundos | 2,167 Tokens |
| Gemini 2.5 flash lite | Exitoso | 7 segundos | 2,048 Tokens |
| DeepSeek-chat | Exitoso | 52 segundos | 3,073 Tokens |
| Ollama + deepseek-r1:7b | Fallido | 301 segundos | 1,203 Tokens |
| Groq + openai/gpt-oss-120b | Exitoso | 5 segundos | 3,415 Tokens |
El modelo de Deepseek corriendo en mi máquina evidentemente fue muy lento, ya que no es un equipo especializado, sin siquiera GPUs, pero la verdad el problema no fue el tiempo, sino el resultado. El modelo de Deepseek de 7 billones de tokens fue muy “lerdo” para seguir instrucciones y no logró devolver los resultados en el formato deseado. Sin embargo, el modelo de, aunque fué el mas lento de las APIs, si dió resultados exitosos.
Los demás modelos si lograron todos cumplir de manera exitosa la tarea con muy pocos errores y en general todos fueron coherentes con los resultados generados. Es decir, correr varias veces el proceso con la misma data producía resultados válidos o similares en cada caso.
Como muestra dejo como ejemplo el resumen de mis competencias identificadas por los diferentes modelos, por supuesto los resultados no son iguales, pero en todo caso son congruentes con mi perfil y el análisis es válido:
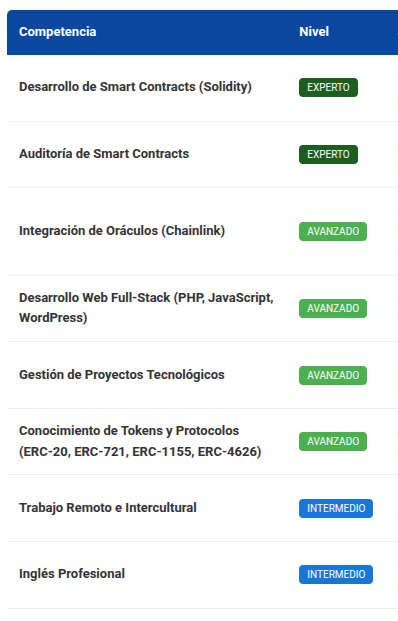
ChatGPT gpt-4.1-mini
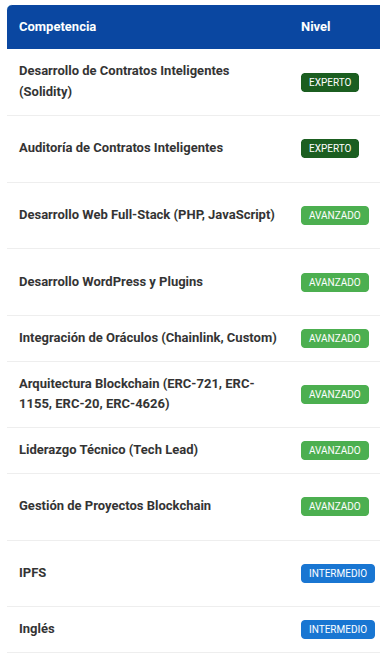
Gemini 2.5 flash lite
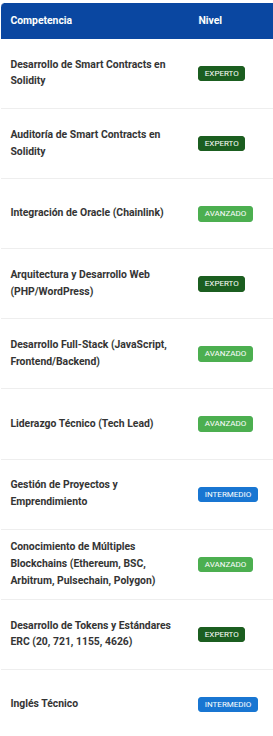
DeepSeek-chat
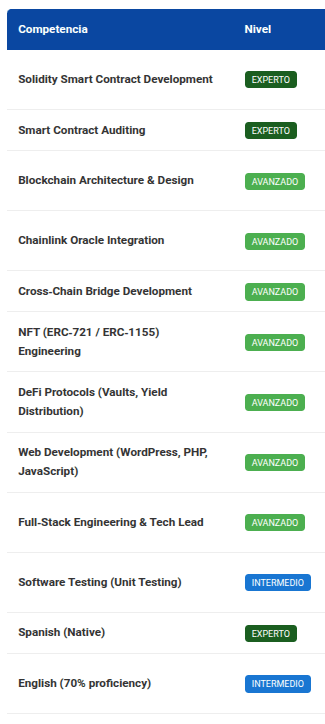
Groq + openai/gpt-oss-120b
Como se ve en las comparaciones anteriores, todos los análisis son congruentes, aunque no 100% iguales. Por ejemplo todos coinciden en mis principales competencias: desarrollo y auditorias en solidity, en mis competencias avanzadas: oráculos, desarrollo web full-stack, protocolos de blockchain y en mi nivel de inglés intermedio. En cuanto al resto de las competencias cada modelo dió resultados diferentes, pero todos son correctos, la diferencia es de matices en la perspectiva del análisis.
Conclusión
El ganador absoluto de esta ronda de pruebas es: Groq* con el modelo abierto de OpenAI, es el más rápido, usa la versión libre de uno de los mejores modelos del mercado (ChatGPT 4), el cual cuenta con la mayor cantidad de parámetros de los modelos del mercado (120 billones), además la plataforma de Groq permite usar este modelo de manera muy económica, y en mi casi, hasta ahora, completamente gratis. No he tenido necesidad si quiera de darles mi tarjeta de crédito.
Además la plataforma de Groq no utiliza GPUs (Graphics Processing Units) sino LPUs (Language Processing Units).
Las GPUs procesan información en paralelo, y son muy útiles en el entrenamiento de una IA, pero al momento de hacer consultas a un modelo ya entrenado, este procesamiento en paralelo pierde relevancia ya que el procesamiento del lenguaje natural es secuencial, además que las GPU tradicionales presentan cuellos de botella en la memoria al momento de procesar prompts.
Estas características han sido mejoradas con los LPU de la empresa Groq.
Veredicto: Groq + openai/gpt-oss-120b es bueno, bonito, barato.
* No confundir Groq con "Q" con Grok con "K", Groq es una empresa fundada por Jonathan Ross, el creador de los TPUs de Google, no Grok de X creado por Elon Musk.


