Hello World!
Three years ago began a technological transition process that materialized with intelligent agents in 2025. In recent years, I have specialized as a Blockchain and smart contract developer. This, coupled with the "Bear Market," caused the demand for my products and services to decline significantly over the last year.
Obviously, Blockchain technology is not going anywhere, but just as the big players in Silicon Valley are all fully focused on Artificial Intelligence today, it seems to me that most technology companies and entrepreneurs of all kinds are directing their efforts to see what they can do with AI.
Gartner qualified 2025 as "The Year of AI Agents," and some reports indicate that more than half of companies are using "some type of AI"... I don't know. Maybe it's because my environment is different, or this technology hasn't hit Central America with such force yet, but I think there is still a lot of hype and little substance; everyone wants to do something, but there are few real implementations.
That is why I have decided to roll up my sleeves and get my hands dirty. I will start writing about my modest discoveries and advances to try to see how far this technology reaches, and if it can really be put into practice for companies and clients in my environment.
Vocational Analysis Agent
I started with what I have closest at hand: PsicoEnLine@, a psychometric testing software I developed together with Psico Consult, a Venezuelan personnel evaluation and selection company specializing in psychometric tests and other instruments. This system produces reports in natural language (using prehistoric technology driven by if-else statements and a table of possible comments); these reports are useful for human resources analysts in their candidate evaluation and selection processes.
After some initial tests with Bedrock (very expensive) and Claude Code (not very user-friendly), I landed on n8n (extremely easy and, for now, dirt cheap, it's free and open source). n8n is an automation tool that integrates very easily with Large Language Models (LLMs). It is marketed as a low-code tool, and yes, it's true, so far I haven't had to "write much code," but you can't teach an old dog new tricks (or in my case, an old dog doesn't stop programming), so I always end up adding a code node here and there to do one thing or another.
n8n can be installed locally very easily:
sudo apt install npm
sudo apt install nodejs
sudo npm install -g n8n
sudo n8n start
I initiated my first "Hello World!", a simple vocational analysis agent. The idea is simple:
- Use a Resume, a psychometric test result, a LinkedIn profile, or any candidate information as input (grades, brief personal description, etc.)
- Request basic user data in a simple form
- Send the relevant data to an LLM to behave like a human resources analyst and evaluate the person's professional potential
- Test different LLMs to evaluate costs, number of tokens spent, and types of responses
- Format the response in HTML and send it by email to the candidate
The resulting flow was:
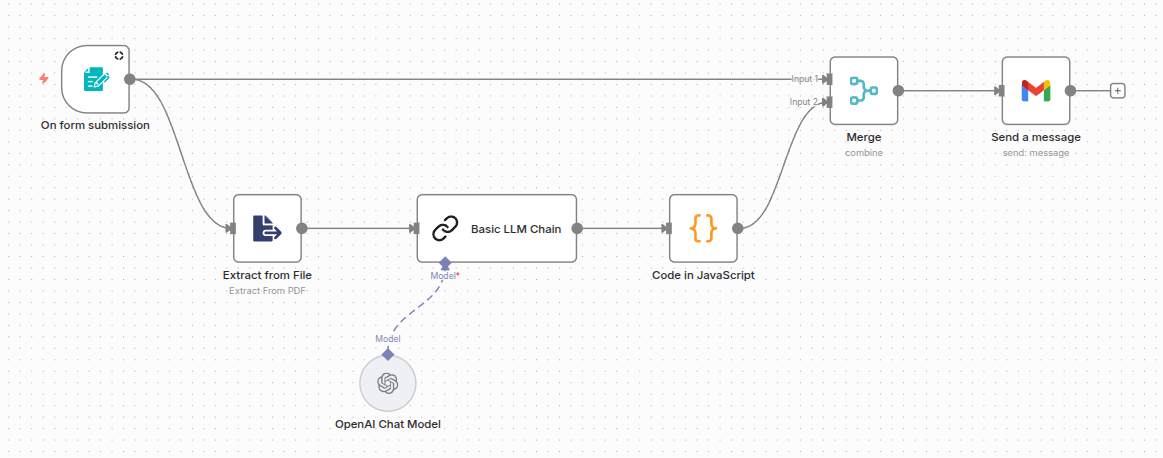
n8n Workflow
Preliminary Results
I ran some tests with various profiles; here is an example of the analysis of my resume, which the agent sent to my email automatically:
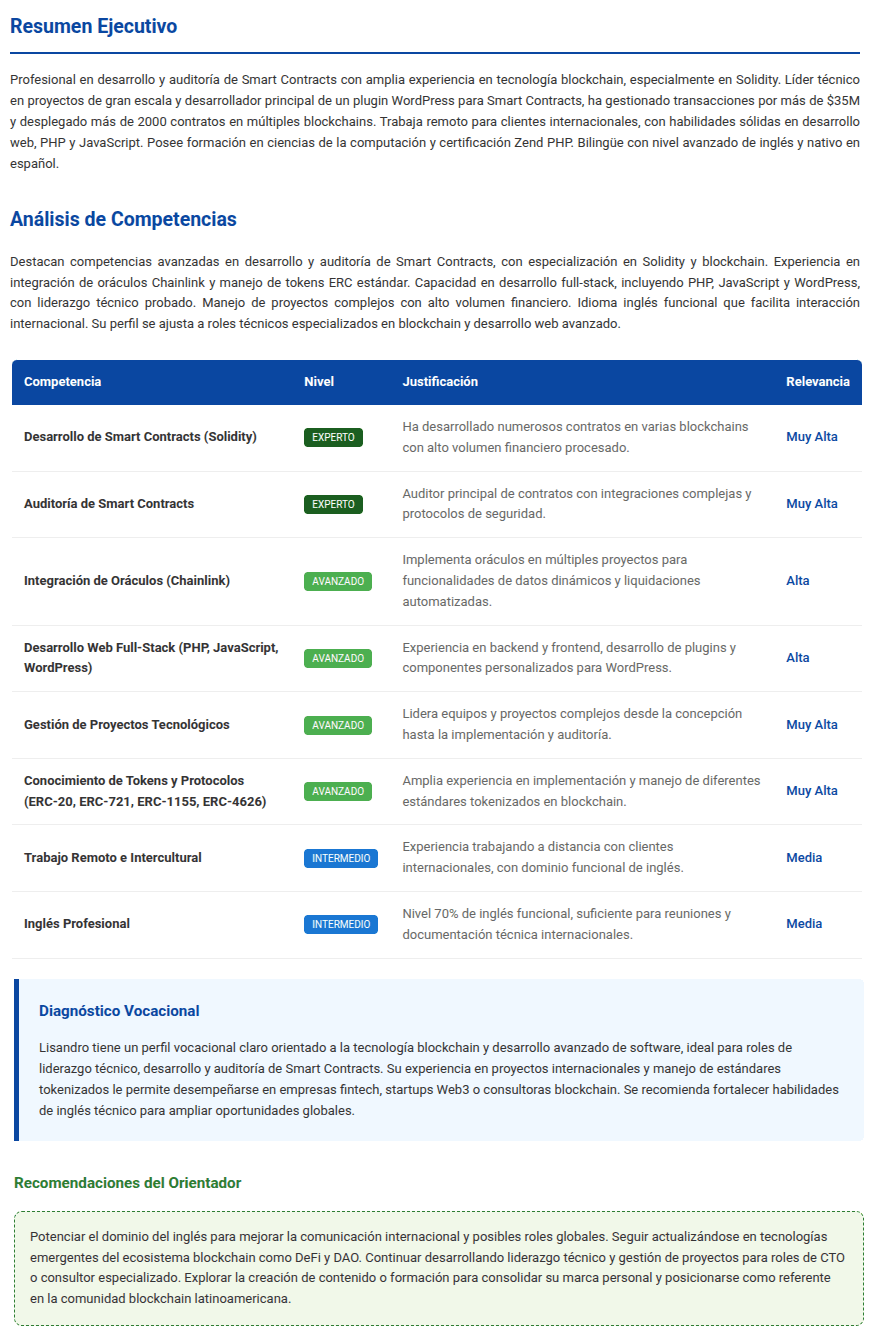
Vocational Analysis Result
After this, I evaluated several different LLM options:
- ChatGPT gpt-4.1-mini: OpenAI's small model. It is the model available in the chat for free, designed for a balance between speed and reasoning.
- openai/gpt-oss-120b: Released in 2025, it is OpenAI's first open-source (open-weights) model. It uses a Mixture of Experts (MoE) architecture that makes it very efficient.
- Gemini 2.5 flash lite: A fast and economical version of the Gemini 2.5 family.
- DeepSeek-chat (V3): DeepSeek's flagship model. It uses a very advanced architecture that rivals GPT-4o in general capacity, but with a much lower operating cost.
- deepseek-r1:7b: A model specialized in pure reasoning. Small in size.
The first step was to classify the models by type:
- API: APIs offered by companies, available at a cost per million input or output tokens.
- Open Source: Versions of LLMs also created by the aforementioned companies, but publicly available to be installed and used independently.
Models invoked via API only require account registration and depositing a sum of money; in my case, for testing, I only credited between $2 and $10 to each one, and I only spent a few cents.
Regarding Open Source, I only needed to install the 7-billion parameter DeepSeek-r1 on my machine, because I could use OpenAI's Open Source model using the Groq API (yes, with a "Q", not Grok with a "K" by Elon Musk).
The installation of ollama + deepseek was very simple and took only a few minutes:
curl -fsSL https://ollama.com/install.sh | shAnd to run it:
ollama serveAfter running a dozen tests locally on my simple Laptop (AMD Ryzen™ 7 + 16Gb RAM) using n8n locally, the performance was as follows:
Performance Results
| Model | Result | Response Time | Tokens Used |
|---|---|---|---|
| ChatGPT gpt-4.1-mini | Successful | 15 seconds | 2,167 Tokens |
| Gemini 2.5 flash lite | Successful | 7 seconds | 2,048 Tokens |
| DeepSeek-chat | Successful | 52 seconds | 3,073 Tokens |
| Ollama + deepseek-r1:7b | Failed | 301 seconds | 1,203 Tokens |
| Groq + openai/gpt-oss-120b | Successful | 5 seconds | 3,415 Tokens |
The DeepSeek model running on my machine was evidently very slow, as it is not specialized equipment, not even equipped with GPUs, but honestly, the problem wasn't the time, but the result. The 7-billion token DeepSeek model was too sluggish to follow instructions and failed to return the results in the desired format. However, the other DeepSeek model, although the slowest of the APIs, did yield successful results.
The other models all managed to successfully complete the task with very few errors, and in general, they were all coherent with the generated results. That is, running the process several times with the same data produced valid or similar results in each case.
As a sample, I leave here an example of the summary of my competencies identified by the different models; of course, the results are not identical, but in any case, they are congruent with my profile and the analysis is valid:
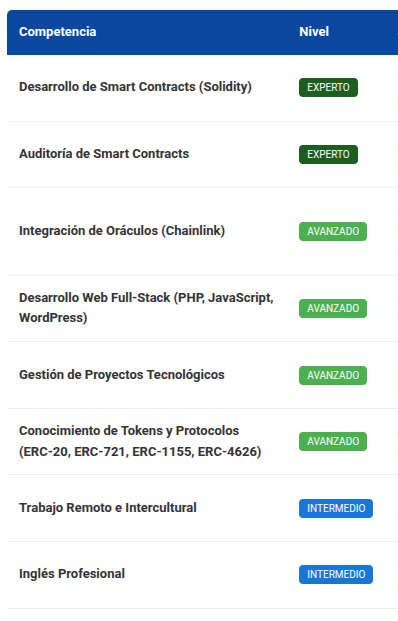
ChatGPT gpt-4.1-mini
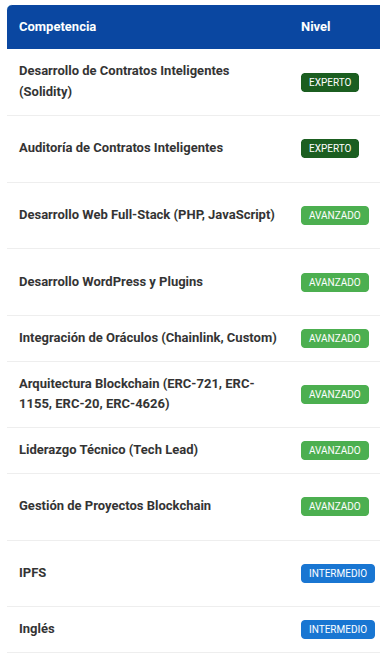
Gemini 2.5 flash lite
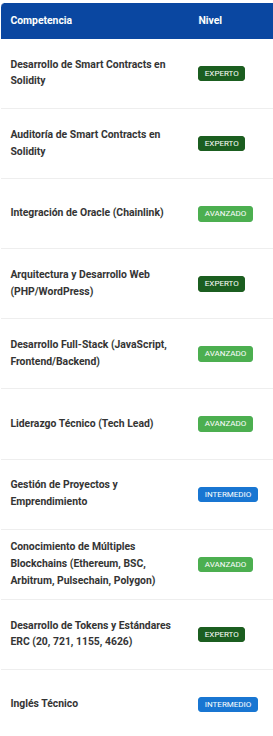
DeepSeek-chat
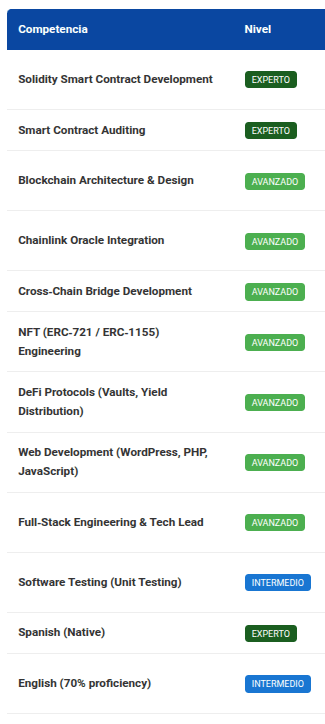
Groq + openai/gpt-oss-120b
As seen in the previous comparisons, all analyses are congruent, although not 100% equal. For example, they all coincide on my main competencies: development and auditing in Solidity; on my advanced competencies: oracles, full-stack web development, blockchain protocols; and on my intermediate English level. regarding the rest of the competencies, each model gave different results, but all are correct; the difference lies in the nuances of the analysis perspective.
Conclusion
The absolute winner of this round of testing is: Groq* with OpenAI's open model. It is the fastest, it uses the free version of one of the best models on the market (ChatGPT 4), which boasts the largest number of parameters among market models (120 billion), and furthermore, the Groq platform allows using this model very economically, and in my case, so far, completely free. I haven't even needed to give them my credit card.
Additionally, the Groq platform does not use GPUs (Graphics Processing Units) but LPUs (Language Processing Units).
GPUs process information in parallel and are very useful in training an AI, but when querying an already trained model, this parallel processing loses relevance since natural language processing is sequential. Furthermore, traditional GPUs present memory bottlenecks when processing prompts.
These characteristics have been improved with the LPUs from Groq.
Verdict: Groq + openai/gpt-oss-120b is good, nice, and cheap.
* Do not confuse Groq with "Q" with Grok with "K"; Groq is a company founded by Jonathan Ross, the creator of Google's TPUs, not Grok from X created by Elon Musk.


